")
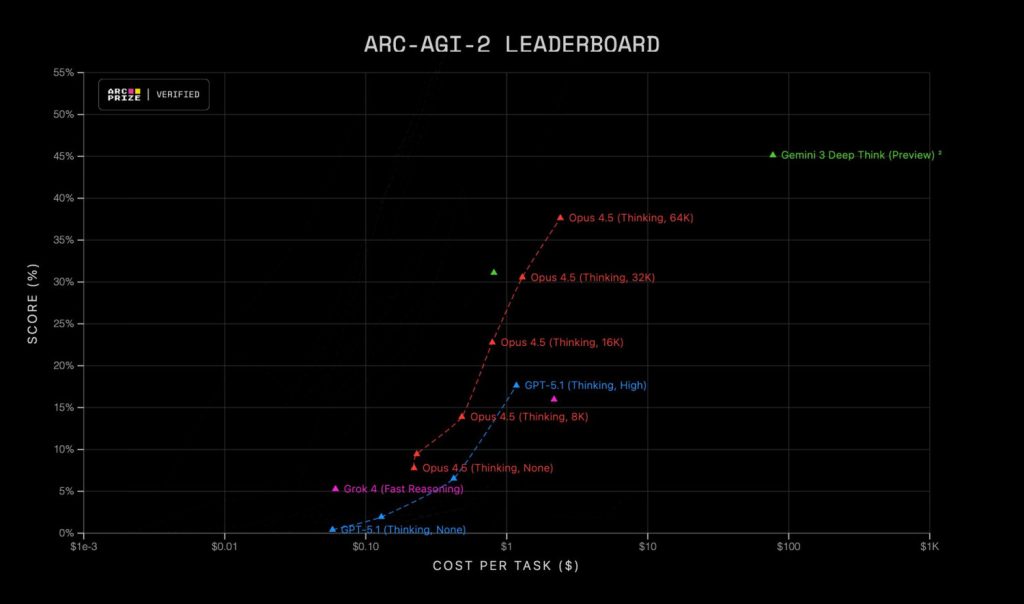
Як інформує «Перший Новинний» з посиланням на X-акаунт проєкту ARC Prize, після виходу Claude Opus 4.5 дослідники оновили показники зазначеної моделі штучного інтелекту (ШІ) в бенчмарках ARC-AGI-1 і ARC-AGI-2. У першому тесті зафіксовано 80% при вартості виконання завдання $1,47. У другому — 37,64% при вартості $2,40.
ARC-AGI являє собою серію випробувань на абстрактне мислення, в яких ШІ-моделі потрібно виділити правило з декількох прикладів і застосувати його для вирішення наступної головоломки. Людині подібні завдання зазвичай даються без зусиль, проте здатність переносити знання на нові варіанти завдань у нейромереж сформувалася лише в нових поколіннях ШІ та вважається найважливішим елементом майбутніх автономних систем.
В ARC-AGI-1 Opus 4.5 і ряд інших систем досягли рівня розсудливості, наближеного до людського. Однак дослідники вважають, що цей набір давно застарів, а частина його змісту могла потрапити в навчальні бази. Сучасна версія тесту ARC-AGI-2 захищена значно краще, тому її результати сприймаються як більш об’єктивні. Opus 4.5 з показником 37,64% впевнено обігнав попереднього лідера — Gemini 3 Pro з приблизно 31%. При цьому дистанція до людського рівня залишається істотною — близько 66%.
Opus 4.5 є новою флагманською ШІ-системою Anthropic і продемонструвала перевагу над продуктами Google та OpenAI в безлічі бенчмарків, включаючи SWE-Bench Verified, який вважається провідним тестом в області програмування. Додатково розробники знизили вартість API втричі — до $5 за мільйон вхідних токенів і $25 за мільйон вихідних. Модель витрачає токени значно економніше в завданнях підвищеної складності, що робить її використання в ряді сценаріїв навіть дешевшим за попередню версію — Claude Sonnet 4.5.
Раніше ми писали про те, що GPT-5.1-Codex-Max випередив Gemini 3 Pro на 76,2% у бенчмарку.